記事の概要
この記事では,機械学習手法であるdoc2vecを用いてニュース記事を30次元のベクトルで表現した結果について紹介していきます.
また記事をベクトル化する過程で,文を品詞ごとに区切る処理(形態素解析)が必要となるのですが,その処理についても紹介していきます.
doc2vecの紹介
doc2vecで得られるもの
doc2vecモデルへ大量の分かち書きされた文書データを入力すると,
- 入力した文書を表現するM次元ベクトル
- 入力した文書群中に出現した単語を表現するM次元ベクトル
- 入力された分かち書きされた文書データを表現するM次元ベクトルを出力する推定器
の3つが得られます.この入出力関係を以下の図に載せます.
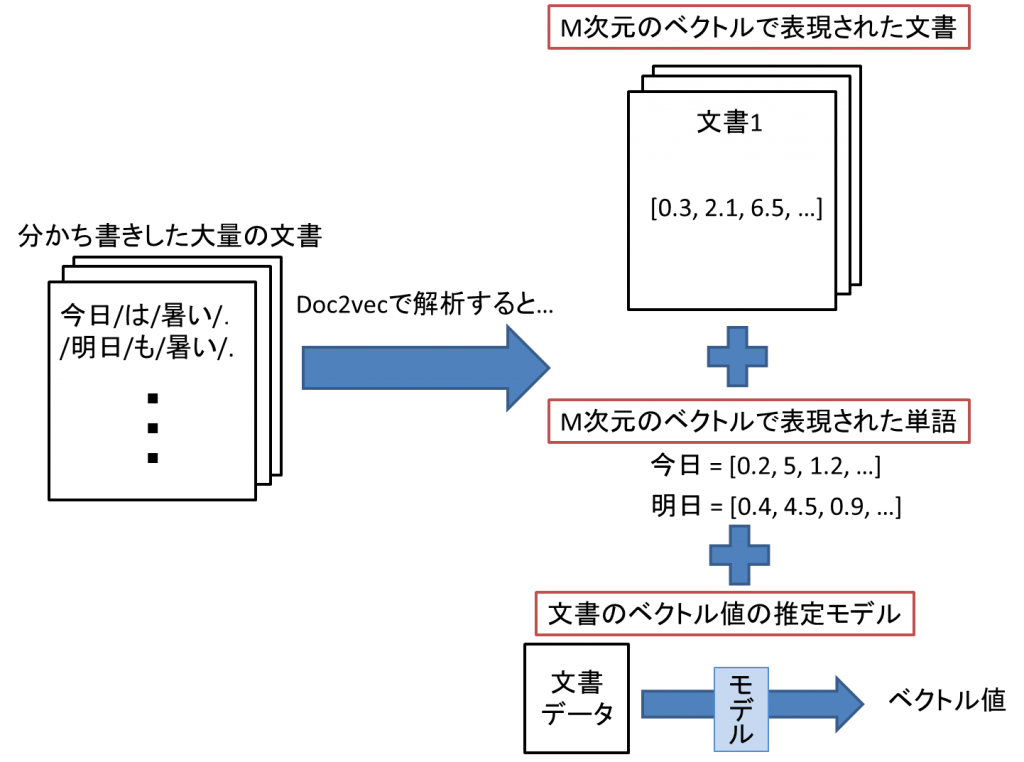
doc2vecに文書データを与えることで得られるもの一覧
ここで,ベクトルの次元はハイパーパラメータとなっており,自身で設定する必要があります.どのくらいの次元に設定すべきかはわかりませんが,大きければ大きいほど解析に時間がかかってしまうため,そのあたりも考慮して決定した方が良いですね.後ほど詳細に述べますがwikipediaの全日本語記事を用いて解析を行う場合,100次元では10日経っても終わらなかったので泣く泣く30次元にしました.
doc2vecの仕組み
doc2vecの仕組みを理解するためには,まず単語をベクトル化する手法であるword2vecの仕組みを理解する必要があります.
word2vecでは,ある単語Aをどのようなベクトルで表現するか判断するための情報として,文書中に出現した単語Aの前後n単語にどのような単語が出現しているかを用います.
詳しくは絵で理解するWord2vecの仕組みというサイトでわかりやすく説明されていますので,そちらをご覧ください.
doc2vecは上記のword2vecを拡張した手法です.
Doc2Vecの仕組みとgensimを使った文書類似度算出チュートリアル
というサイトでその仕組み,およびpythonでdoc2vec解析を行う方法について記述されています.
natto-pyの紹介
日本語の文書データを分析するためには,形態素解析を行って品詞ごとに区切る必要があります.ありがたいことに,形態素解析エンジンであるMecabというソフトウェアがオープンソースで公開されています.
MeCab: Yet Another Part-of-Speech and Morphological Analyzer
これを用いることで無料で形態素解析が行えるようになります.
このMecabをpython上で扱えるようにするためのlibraryとして,
- mecab-python
- natto-py
の二種類があります.このうち,natto-pyの方が導入が楽だと感じたので,natto-pyを用いて解析を行いました.それぞれのwindowsへのインストール方法は以下のサイトで詳しく述べられていますので,そちらをご覧ください.
PythonとMeCabで形態素解析(on Windows)
Python の MeCab バインディング natto-py を使う
分かち書きするスクリプトの紹介
【自然言語処理】得られたニュース記事をgensim, nattoライブラリを用いてベクトル化する【python】
で得られたニュース情報を格納したデータフレームに,分かち書きした内容を加えるスクリプトを紹介します.
from natto import MeCab
#demo_natto.py
#引数POSで,抽出する品詞を指定
def keitaiso(newsdata,POS = ["名詞","動詞","形容詞"]):
nm = MeCab()
seplist = []
for index,row in newsdata.iterrows():
contents = row["contents"].encode("shift-jis","ignore")
#ここでmecabを用いて形態素解析を行う
wakachi = nm.parse(contents.decode("cp932"),as_nodes = True)
txt = []
for n in wakachi:
node = n.feature.split(",")
if(POS != None):
if(node[0] in POS):
txt.append(node[6])
else:
continue
else:
txt.append(node[6])
seplist.append(txt)
newsdata["wakachi"] = seplist
return newsdata
if __name__ == "__main__":
append_newsdata = keitaiso(newsdata)
このスクリプトによって文を分かち書きし,名詞,動詞および形容詞を抽出することが可能です.なお,動詞は原形に直して抽出しています.
試しに分かち書きしてみた結果を以下に載せます.
‘\u3000無人レジの米ベンチャー企業、スタンダードコグニション(SC、カリフォルニア州)が日本に上陸、日本最大の日販品卸のパルタックと提携して本格的に動き出した。米国ではインターネット大手のアマゾン・コムが無人店舗「アマゾンゴー」を1月に発表し話題となったが、SCはそのライバルとして注目されている企業だ。\u3000日本では既にGUやイオン、JR東日本などが…
↓
[‘無人’, ‘レジ’, ‘米’, ‘ベンチャー企業’, ‘スタンダード’, ‘cognition’, ‘*’, ‘カリフォルニア州’, ‘日本’,’上陸’, ‘日本’, ‘最大’, ‘日販’, ‘品’, ‘卸’, ‘パルタック’, ‘提携’, ‘する’, ‘本格’, ‘的’, ‘動き出す’, ‘米国’, ‘インターネット’, ‘大手’, ‘アマゾン’, ‘コム’, ‘無人’, ‘店舗’, ‘*’, ‘1月’, ‘発表’, ‘する’, ‘話題’, ‘なる’, ‘*’, ‘ライバル’, ‘注目’, ‘する’, ‘れる’, ‘いる’, ‘企業’, ‘日本’, ‘*’, ‘イオン’, ‘JR東日本’, …]
適切な位置で区切れていると思います.元の文に存在する\u3000ですが,これはunicodeにおいて全角スペースを表す文字コードです.windowsで文を扱うためshift-jisに変換しているのですが,その過程で変換が行えずそのまま出現しちゃっている次第です.
doc2vecモデルの作成
wikipediaの日本語記事を用いてモデルを作成しました.学習に用いるデータによってどんなベクトルが記事および単語に割り当てられるか変わってきますので,様々な文書データでモデルを構築してみると面白いかもしれません.
Doc2Vec を使って日本語の Wikipedia を学習する
こちらの記事のコードを利用させていただきました.こちらの記事では500円払うことでベクトルを100次元に設定したモデルのソースが得られるようです.
500円をケチって自分でモデルづくりを行いました.私のマシーンのスペックでは,100次元では1週間回し続けても学習が終わらなかったため,泣く泣く30次元に設定してモデルづくりを行いました.それでも1週間ほどかかってしまいましたが.
ちなみにPCのスペックは
CPU:Intel(R)Core(TM) i5-2540M CPU @ 2.60GHz 2.60GHz
メモリ:8GB
です.
ニュース記事をベクトル化してみた結果
249記事の本文をベクトル化してみました.文書を表現するベクトルを表示しても何が何だかわからないので,記事ごとにベクトル的に最も似ている記事を抽出してみました.ここで,ベクトル同士の近さの定義として,コサイン類似度を用いました.コサイン類似度の性質は以下の通りです.ベクトルを正規化して内積をとることで得られます.正規化するため長さの情報が失われてしまうため,その影響がどれほど存在するのか気になるところです.
各記事に最も近い記事とその類似度をまとめた表をの一部を以下に載せます.この結果の妥当性については主観でしか判断できないため,なんとも言えませんがまあ概ね合っているのではないのでしょうか.
| title | most_similar_title | cos |
|---|---|---|
| 【高論卓説】無人レジの米ベンチャーが日本上陸 導入コストの低さがウリ、今後に大注目 松… | 無人タクシー近くお目見え 世界初、米でグーグル系 | 0.823070645 |
| 自動運転で複数車同時走行 愛知県、遠隔での実験は初 | 三菱ふそう、エレベーター付き観光バスで攻勢 五輪へバリアフリー対応強化 | 0.829068661 |
| 血糖値測定レンズ開発停止 グーグル系医療関連会社 | ソフトバンク上場 孫氏、投資に集中へ 通信事業には懸念も | 0.797219396 |
| 米の共同工場を着工 トヨタとマツダ | 造船安売りに危機感、韓国の過剰補助金に日本企業連携 | 0.710374951 |
| 日産、中国に活路…現地ブランドでニーズくみ上げ | 中国市場“変調”の中…広州モーターショー開幕 | 0.877313256 |